


В этой части разберем технику улучшения производительности стратегии, использующую множество моделей.
Одним из наиболее мощных методов улучшения прибыльности вашей модели является объединение нескольких алгоритмов в так называемое "множество". Теория состоит в том, что комбинируя разные модели и их предсказания, мы получаем более робастные результаты. Тесты показывают, что даже объединение простых моделей может быть производительнее более сложной, но единственной стратегии.
Существует три основных техники объединения:
Смешивание:
Смешивание основано на создании моделей, прогоняемых на немного различных тренировочных наборах и усреднения их результатов для получения одного предсказания. Тренировочный набор переделывается путем повторения или удаления вхождений данных, в результате чего получается несколько разных наборов. Этот процесс работает хорошо для нестабильных алгоритмов (например, деревья решений) или, если присутствует определенная степень случайности в процессе создания моделей ( как, например, начальные веса в нейронных сетях). Получив усредненное предсказание для коллекции моделей с высоким значением подгонки, мы можем уменьшить результирующую подгонку без увеличения недооценки, что приведет к лучшим результатам.
Форсирование:
Форсирование представляет собой пошаговый процесс стимулирования моделей к улучшению их результатов в тех местах, где ранее они показывали низкую производительность. Большие веса присваиваются диапазонам исходных данных, ранее неправильно классифицированных, и окончательное предсказание получается путем комбинирования взвешенного "голосования" всех моделей в множестве. Эта техника хорошо работает со "слабыми" классификаторами с тенденцией к недооценке данных, таких как простые деревья решений и наивный байесовский классификатор. Здесь используются алгоритмы с высокой недооценкой , множество которых в целом позволяет лучше детектировать необходимый сигнал.
Упаковка:
Ранее мы рассматривали множества, содержащие модели с одним и тем же алгоритмом, но разными параметрами. Что если у нас имеется множество моделей с разными алгоритмами? Упаковка включает широкий спектр моделей с использованием "метаобучения", позволяющего составить наилучшую комбинацию отдельных моделей. Предсказания, сделанные каждой моделью, подаются далее в "метаобучение", которое анализирует характеристики каждой модели и выдает окончательное предсказание. Упаковку лучше всего применять, когда вы владеете коллекцией моделей, основанных на отличных друг от друга алгоритмах.
Применим модель с высокой дисперсией результатов, простое дерево решений, чтобы продемонстрировать, как смешивание улучшает производительность.
Сначала, построим дерево решений, используя те же индикаторы, что и при создании наивного байесовского классификатора из части 1:
install.packages(“rpart”) library(rpart) install.packages(“foreach”) library(foreach) BaselineDecisionTree<-rpart(Class~EMA5Cross+RSI14ROC3+VolumeROC1,data=FeatureTrainingSet, cp=.001)
Посмотрим, как модель ведет себя на тестовой выборке:
table(predict(BaselineDecisionTree,FeatureTestSet,type="class"),FeatureTestSet[,4],dnn=list('predicted','actual'))
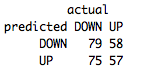 Доля правильных предсказаний около 51%. Сравнивая этот результат с долей на тренировочном наборе, которая была равна 73%, мы делаем вывод, что наше дерево решений имеет высокую подгонку под тренировочную выборку.
Доля правильных предсказаний около 51%. Сравнивая этот результат с долей на тренировочном наборе, которая была равна 73%, мы делаем вывод, что наше дерево решений имеет высокую подгонку под тренировочную выборку.
Давайте посмотрим, как техника смешивания поможет уменьшить подгонку. Язык R предоставляет пару различных алгоритмов смешивания, но мы создадим такой алгоритм самостоятельно, для лучшего управления параметрами смешивания:
length_divisor<-10
iterations<-1501
#Эти операторы определяют как мы создаем разные тренировочные наборы и сколько моделей включить во множество. Мы строим 1501 модель на случайных выборках по 1/10 от всех данных
BaggedDecisionTree<- foreach(m=1:iterations,.combine=cbind) %do% { training_positions <- sample(nrow(FeatureTrainingSet), size=floor((nrow(FeatureTrainingSet)/length_divisor)))
train_pos<-1:nrow(FeatureTrainingSet) %in% training_positions
BaselineDecisionTree<-rpart(Class~EMA5Cross+RSI14ROC3+VolumeROC1,data=FeatureTrainingSet[train_pos,])
predict(BaselineDecisionTree,newdata=FeatureTestSet)
}
#Это наш алгоритм смешивания.
CumulativePredictions<-apply(BaggedDecisionTree[,1:iterations],1,function(x){s<-(sum(x)/iterations)
round(s,0)})
#Сейчас нужно агрегировать предсказания наших 1501 моделей
FinalPredictions<-ifelse(CumulativePredictions==1,"DOWN","UP")
#Возвращаем решение - бинарный выбор из нашей классификации (цена возросла/снизилась)
Снова проверяем производительность на тестовой выборке (так как дерево создано на случайных диапазонах из тренировочного набора, мы можем получить несколько разные результаты - это один из недостатков работы с нестабильными алгоритмами):
table(FinalPredictions,FeatureTestSet[,4],dnn=list('predicted','actual'))
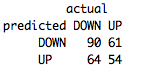 Намного лучше! Из-за уменьшения дисперсии нам удалось увеличить нашу производительность до 54%. В окончании, возьмем лучшую модель и прогоним ее на проверочной выборке, чтобы удостовериться, что мы построили робастный алгоритм.
Намного лучше! Из-за уменьшения дисперсии нам удалось увеличить нашу производительность до 54%. В окончании, возьмем лучшую модель и прогоним ее на проверочной выборке, чтобы удостовериться, что мы построили робастный алгоритм.
Пока смешанные деревья решений на проверочной выборке и наивный байесовский классификатор из части 1 на тестовой выборке работают примерно с одинаковой производительностью. Автор отмечает, что ему больше нравятся модели с высокой недооценкой, чем с высокой подгонкой. Модели с тенденцией к недооценке могут работать не так хорошо на тренировочной и тестовой выборке, но вы можете быть уверены, что они покажут те же результаты на новых данных. Модели с высокой подгонкой, с другой стороны, имеют высокий риск показать значительно более низкую производительность в этом случае.
По этим соображением, применим технику смешивания к нашему наивному байесовскому алгоритму. И в результате прогона на проверочном наборе получаем:
table(predict(FeatureNB,FeatureValSet),FeatureValSet[,4],dnn=list('predicted','actual'))
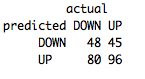 Неплохо, и очень похоже на производительность на тренировочной и тестовой выборках! Наша окончательная производительность на проверочной выборке составила 54%. Значит мы построили хорошую робастную модель.
Неплохо, и очень похоже на производительность на тренировочной и тестовой выборках! Наша окончательная производительность на проверочной выборке составила 54%. Значит мы построили хорошую робастную модель.
Заключение.
Первый шаг к увеличению производительности вашей модели - это понимание, в каком случае она подвержена недооценке/подгонке. Если вы сможете определить эти состояния, значит сможете и предпринять необходимые исправления.


Сообщение