
Предлагаю перевод интересной статьи с сайта www.inovancetech.com о нетрадиционном применение техник машинного обучения: Machine Learning Techniques to Improve Your Strategy.
Машинное обучение это мощный инструмент не только для создания новых стратегий, но и для повышения эффективности уже существующих.
В этой статье мы осветим вопрос управления размером позиции с использованием алгоритма Random Forest (RF) и включения/выключения торговли на основе модели скрытых состояний Маркова (HMM). Мы предполагаем, что у вас уже есть торговая стратегия.
Как улучшить управление позицией
Управление позицией - это очень важный аспект трейдинга, которому часто не уделяется должное внимание. Многие трейдеры смотрят на управление позиции с точки зрения уменьшения риска убытков, но не инструмента увеличения прибыльности стратегии. Конечно важно избегать большого риска, используя небольшую часть торгового счета ( не более 2%) в каждой сделке, но лучший способ - это применение фиксированного лота или фиксированного процента от вашей максимальной позиции для каждого трейда.
Логично входить в позицию большим сайзом, когда сделка имеет большую вероятность прибыли и малым сайзом, когда вы менее уверены в сделке. Используя RF, популярный алгоритм машинного обучения, мы можем вычислить вероятность прибыли для каждой сделки и размера позиции совместно ( не рискуя, конечно более чем 2% капитала).
Более подробно применение RF было рассмотренно в статье о стратегии с применением диапазона Боллинджера для валютной пары GBP/USD, и мы используем подобный подход для определения оптимального размера позиции.
Используя мой набор прошлых сделок по указанной стратегии (вы можете скачать его здесь), во первых, мы классифицируем каждую сделку по трем категориям, основываясь на их доходности:
- Прибыльные сделки: прибыль более 10 тиков - в идеале мы хотим входить большей позицией в эти сделки
- Нейтральные сделки: прибыль менее 10 тиков и убыток менее 10 тиков - здесь будем использовать позицию по умолчанию
- Убыточные сделки: убыток более 10 тиков - здесь мы должны входить с малым размером позиции
Далее решим, какую информацию мы хотим использовать для принятия решений, то есть что подавать на вход модели. Эта область, где вы должны использовать свой опыт для собственной стратегии. Предложим несколько вариантов:
- Текущие рыночные условия. Вход: волатильность, трендовый или флэтовый рынок и т.д. Это применимо, если ваша стратегия работает лучше в определенных рыночных состояниях.
- Прибыльность в прошлом. Вход: прибыль в последних n сделках. Если вы заметили, что стратегия имеет продолжительные периоды, где она работает хорошо и периоды, где ее эффективность низка, то возможно это ваш случай.
- Внешние факторы. Вход: анонсы важных новостей, праздники, определенные дни недели и т.д. Если вы избегаете торговли при определенных внешних обстоятельствах, то можете использовать данный подход.
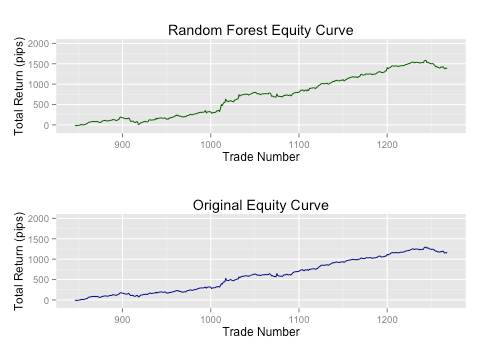
Попробуем использовать прибыльность за последние 3 дня для определения позиции в следующей сделке ( вы можете скачать здесь код на языке R). Мы удваиваем размер позиции, если модель предсказывает. что следующая сделка будет прибыльной ( с прибылью более 10 тиков), уменьшаем в два раза, если будет предсказание убыточной сделки ( убыток более 10 тиков), и оставляем размер неизменным при нейтральной сделке. Мы обучаем модель на первых двух третях выборки и тестируем на последней трети - выборке out-of-sample. График прибыли показан в заглавии статьи.
Мы достигли 20% увеличения общей прибыли и прибыль на одну сделку возросла с 2,8 пункта до 3,3 пунктов просто при использовании базовой модели. Совсем неплохо!
Когда включать/выключать вашу стратегию
Знание моментов включения или отключения торговли может определять разницу между успехом и потерями вашей стратегии. Тем не менее, определение момента выключения непростая задача. Мы снова будем использовать известный алгоритм машинного обучения - модель скрытых состояний Маркова, для определения режимов рынка, при которых наша стратегия убыточна и мы должны остановить торговлю (смотрите статью по идентификации рыночных условий с помощью HMM).
Сначала мы должны решить, что будем использовать для идентификации различных режимов эффективности стратегии. Зададимся вопросом - какие факторы сигнализируют о том, что мы должны прекратить торговлю?
Попробуем использовать два вычисления, основанных на 10 периодной простой скользящей средней (SMA) нашей кривой прибыли. Рассмотрим два показателя - коэффициент изменения на 5 периодном отрезке и расстояние между текущей точкой кривой прибыли и значением SMA. Коэффициент изменения (ROC) должен сигнализировать о том, что наша кривая находится в падающем тренде, и расстояние между линиями даст нам чувствительный индикатор эффективности стратегии.
Основываясь на этих двух входных значениях, мы применим HMM с двумя состояниями для принятия решения об отключении нашей стратегии (код на языке R можете скачать здесь):
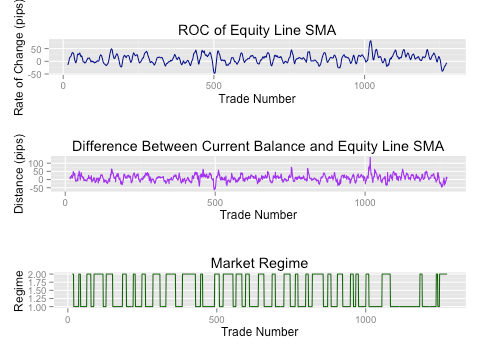
Затем рассмотрим производительность стратегии при остановке торговли при определении моделью "режима 2":
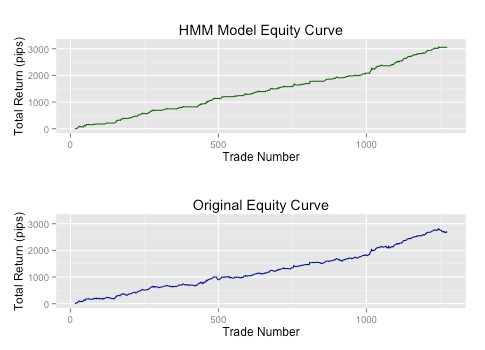
Снова, мы видим значительное увеличение эффективности! 13% рост прибыли, при уменьшении количества сделок с 1259 до 726, почти удваивает прибыльность на сделку с 2,1 до 4,2 пункта и увеличивает точность предсказания с 60% до 67%!
Комбинация RF алгоритма и HMM
В заключении посмотрим, что произойдет, если мы совместим нашу модель оптимального определения позиции с помощью RF и модель определения режимов на HMM для выборки out-of-sample:
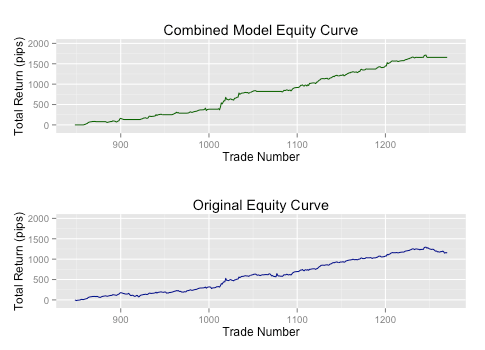
При использовании совмещенных моделей мы видим значительное увеличение эффективности нашей стратегии. Результирующая прибыль выше на 44% при количестве сделок на 133 меньше, чем в первоначальной стратегии, что привело к увеличение прибыли на сделку с 2,7 пункта до 5,7 пунктов, а точность предсказания увеличилась с 64% до 70%.
Таким образом, алгоритмы машинного обучения могут стать мощным инструментом в вашем арсенале для увеличения эффективности используемых стратегий.


Посмотрел бегло код на R ( хотя не являюсь знатоком этого языка ) , но чтото я там не нашел разбиения набора на тренировочный и тестовый. Похоже , автор статьи показывает результаты по тренировочному набору, что в принципе не верно
Нет, разделение на тренировочный и тестовый наборы есть - смотрите файл ml-random-forest-r.txt в архиве:
# Build the training and test data sets
xtrain< -Inputs[1:846,2:4]
ytrain< -Inputs[1:846,1]
xtest< -Inputs[847:1269,2:4]
В random forest разбиение есть, его нет почему то в hmm - где принимается решение - торговать или нет по эквити счета. Просто в трейдерской тусовке постоянно обсуждается тема- можно ли улучшить результат системы - анализируя эквити- пока большинство пытавшихся это сделать не достигли результатов. А тут - прямо грааль! Но похоже- все таки курвафиттинг 🙂