
Интересные соображения по поводу вычисления правильной корреляции изложил в своем блоге Eran Raviv. По моему мнению данный подход можно попробовать использовать в статистическом арбитраже и парном трейдинге. Ниже даю полный перевод статьи с кодом на языке R.
В случае постоянной скорости, время и расстояние полностью коррелированы. Дайте мне одну переменную, я дам вам другую. Когда две переменные не имеют ничего общего между собой, мы говорим, что они не коррелированы.
Вы думаете, что это все, что можно сказать, но это не так. Как правило, ситуация более сложная. В большинстве обычных применений используется корреляция Пирсона. Коэффициент корреляции Пирсона отражает линейную зависимость. Поэтому мы говорим, что это параметрический показатель. На самом деле он может возвращать ноль даже если две переменные полностью зависимы ( наглядно показано здесь).
Реже применяются следующие показатели корреляции:
- ранговая корреляция Спирмена;
- ранговая корреляция Кендалла.
Эти коэффициенты относятся к корреляции Пирсона как медиана (в статистике) к среднему значению. Мы используем порядок вместо значений. Это непараметрические показатели, но они также не говорят совсем ничего о форме зависимости. Что имеется в виду под формой зависимости? Скажем, форма корреляции между двумя переменными х и у плоская, следовательно, неважно в какой области распределения х мы находимся, зависимость между х и у точно такая же, как и в другой области распределения. Например, х и у - торгуемые активы, и если корреляция между ними одинакова как в случае падения цен, так и в случае их роста, мы можем предположить, что форма корреляции постоянна. Таким образом, мы говорим о корреляции, принимая во внимание все распределение. Я использую зависимость формы и структуру корреляции попеременно, но предпочитаю вторую.
Перед демонстрацией этого концепта, возникает естественный вопрос, зачем это нужно. Потому что, мы хотим получать прибыль, желательно без риска. Портфели активов, созданные на базе корреляции, могут повести себя неожиданно, когда структура корреляции не до конца понимается. Как правило, неожиданно плохо.
Есть несколько способов проиллюстрировать. что мы имеем в виду под структурой корреляции, и как она отличается от периода корреляции. Мы используем корреляцию приращений акций и бондов. Возьмем данные двух ETF: SPY и TLT, которые отражают доходность акций и бондов соответственно. Рассмотрим следующие графики:
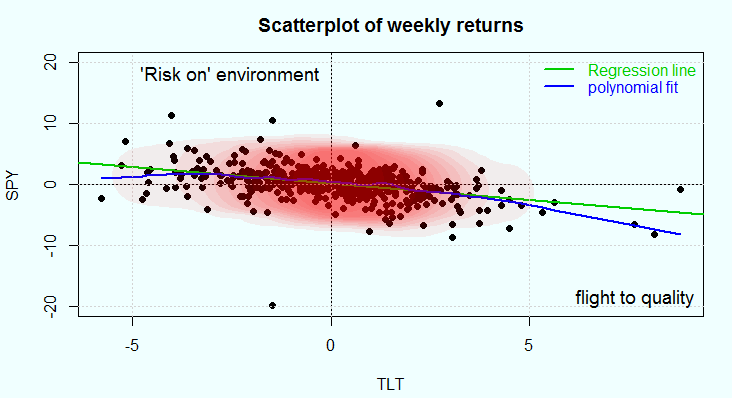
График в заглавии поста
показывает недельные приращения цены SPY по отношению к таким же приращениям TLT. Зеленая линия регрессии показывает среднюю корреляцию между ними. Мы можем сказать, что в среднем,когда бонды растут, акции падают. Если цена акций низкая, приращения цены бондов более высокие. Синия линия (полиномиальная подгонка) как минимум показывает, что структура корреляции не постоянная вдоль совместного распределения приращений. Уклон резче в нижнем правом квадранте. Когда рынок становится волатильным, инвесторы переходят в качественные активы, например, в американские казначейские бумаги. В верхнем левом квадранте предпочтение отдается акциям, это вид рискового поведения инвесторов. Все это подтверждает простое предположение о существовании соревновательности между двумя этими типами активов.
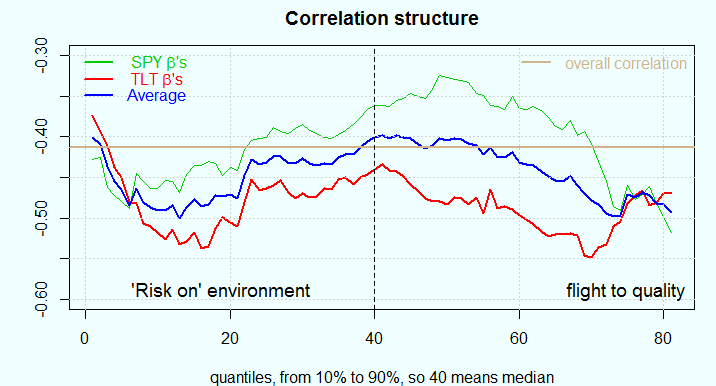
График ниже
создан с использованием теории, представленной в работе Dirk G. Baur : The Structure and Degree of Dependence . Идея состоит в вычислении степени зависимости (беты), используя квантильную регрессию по всем квантилям распределения. Например, зеленая линия - это коэффициенты недельных приращений цены SPY ETF , которые получены при вычислении их регрессии на недельные приращения цен TLT. Красная линия - это коэффициент ( или чувствительность, бета) регрессии приращений TLT на приращения SPY. Отметим, что в отличие от обычного метода наименьших квадратов ( или усредненной регрессии) квантильная регрессия используется для вычисления коэффициента зависимости от определенного квантиля распределения величины ( приращения цены в нашем случае). Это позволяет нам характеризовать полную структуру корреляции. В выше указанной статье Baur не касается вопроса, какой актив на правой стороне регрессии, а какой на левой. Так как беты в этих случаях очевидно разные, мы усредняем их. Синия линия это средняя красной и зеленой линий, а коричневая линия - это эмпирический коэффициент корреляции Пирсона, который мы можем описать как безусловную линейную корреляцию.
Ниже даны коды на языке R для нахождения регрессий и построения графиков.
library(quantmod)
library(MASS)
library(quantreg)
sym = c('SPY', 'TLT')
l=length(sym)
end<- format(Sys.Date(),"%Y-%m-%d")
start<-format(as.Date("2005-01-01"),"%Y-%m-%d")
dat0 = (getSymbols(sym[1], src= "yahoo", from=start, to=end, auto.assign = F))
n = NROW(dat0)
dat = array(dim = c(n,6,l))
prlev = matrix(nrow = n, ncol = l)
w0 <- NULL
for (i in 1:l){
dat0 = getSymbols(sym[i], src="yahoo", from=start, to=end, auto.assign = F)
w1 <- weeklyReturn(dat0) # maybe daily returns are too noisy
w0 <- cbind(w0,w1)
}
time <- index(w0)
ret0 <- as.matrix(w0)
colnames(ret0) <- sym
ret <- 100*ret0 # move to percentage points
TT <- NROW(ret)
# A needed function:
corquan <- function(seriesa,seriesb,k=10){
if(length(seriesa)!=length(seriesb)){stop("length(seriesa)!=length(seriesb)")}
seriesa <- scale(seriesa)
seriesb <- scale(seriesb)
TT <- length(seriesa)
cofa <- cofb <- NULL
for (i in k:(100-k)){
# The workhorse:
lm0 <- summary(rq(seriesa~seriesb,tau=(i/100)))
lm1 <- summary(rq(seriesb~seriesa,tau=(i/100)))
cofa[i-k+1] < - lm0$coef[2,1]
cofb[i-k+1] <- lm1$coef[2,1]
}
return(list(cofa=cofa,cofb=cofb))
}
temp2 <- corquan(ret[,"SPY"], ret[,"TLT"], k=10)
# First plot ####
####################
par(mfrow = c(2,1),bg='azure', mar = c(4, 4.1, 3, 1.7) )
plot(ret[,"SPY"]~ret[,"TLT"], ty="p", lwd=.8, col = 1, pch=19, ylab="SPY", xlab="TLT",
main="Scatterplot of weekly returns", ylim=c(-20,20))
abline(lm(ret[,"SPY"]~ret[,"TLT"]), col = 3, lwd=2)
abline(v=0,h=0)
dens<- kde2d(ret[,"SPY"], ret[,"TLT"], n=round(TT/10) )
temp_col <- rgb(1,0,0, alph=1/14)
lines(lowess(ret[,"TLT"], ret[,"SPY"],f = 1/6), col=4, lwd=2)
grid()
contour(dens$x, dens$y, dens$z, add=T, col= temp_col, fill=4, drawlabels = F, lwd=55, ty="l")
cornertext("bottomright", "flight to quality") # code for this function in the post:
cornertext("topleft", " 'Risk on' environment") # http://eranraviv.com/adding-text-to-r-plot/
legend("topright", c("Regression line", "polynomial fit"), col = c(3,4), text.col = 3:4, bty="n", lwd=2, lty=1)
# Second plot ####
plot(temp2$cofa, ylim=c(-.6,-.3), ty="l", col=3, ylab="", main="Correlation structure",
xlab= "quantiles, from 10% to 90%, so 40 means median")
lines(temp2$cofb, col = 2, lwd=2)
lines(apply(cbind(temp2$cofb, temp2$cofa), 1, mean),col=4, lwd=2)
aline(cor(ret)[1,2]) ; grid() ; abline(v=40, lty="dashed" )
cornertext("bottomright", "flight to quality")
cornertext("bottomleft", " 'Risk on' environment")
legend("topleft", c(expression(paste( " SPY ", beta, "'s")),
expression(paste( " TLT ", beta, "'s") ),"Average" ),
col=c(3,2,4), bty="n", lty= 1, lwd = lwd1, text.col= c(3,2,4))
legend("topright", c("overall correlation" ), col='tan', bty="n", lty= 1, lwd = lwd1, text.col= 'tan')


{kind=link}
Сообщение