
Стандартный подход к вычислению PIN состоит в нахождении методом максимального правдоподобия ненаблюдаемых параметров 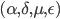 описывающих стохастический процесс трейдов, и последующем вычислением PIN из этих параметров. Мы представим аналитическую оценку токсичности, не требующую промежуточного вычисления ненаблюдаемых величин. Мы обновляем нашу метрику в привязке к объемам для учета скорости прибытия новой информации на рынок. Эта метрика, которая называется VPIN, предоставляет простую оценку токсичности потока ордеров в высокочастотном окружении.
описывающих стохастический процесс трейдов, и последующем вычислением PIN из этих параметров. Мы представим аналитическую оценку токсичности, не требующую промежуточного вычисления ненаблюдаемых величин. Мы обновляем нашу метрику в привязке к объемам для учета скорости прибытия новой информации на рынок. Эта метрика, которая называется VPIN, предоставляет простую оценку токсичности потока ордеров в высокочастотном окружении.
Природа информации и времени
Информация в модели последовательной торговли в общем виде представляет из себя данные, которые несут сообщение о будущем уровне цены актива. На эффективном рынке, значение цены актива отражает его полную информационную величину, в связи с тем, что информированный трейдер стремится получить прибыль от владения этой информацией. Так как маркет-мейкер может занимать как длинную, так и короткую позиции, будущие движения актива влияют на его прибыльность, и он пытается извлечь информацию из паттернов торговли. Эти его попытки отражаются в устанавливаемых уровнях бида и аска.
В высоскочастотном мире маркет-мейкер сталкивается с теми же основными проблемами, хотя временной горизонт, на котором он работает, меняет их в интересном направлении. Высокочастотный маркет-мейкер, удерживающий актив в течении минут, подвержен влиянию событий с подобной же длительностью. Эти информационные события могут иметь фундаментальные причины, но могут и отражать факторы, связанные с природой торгов на всем рынке или со спецификой предоставления ликвидности, имеющих влияние на отдельном интервале. Например, на фьючерсах, информация, которая вызывает увеличение предложения хеджирования данным контрактом, в общем влияет на цену фьючерса, и необходима для принятия решений маркет-мейкером. Это широкое определение информации означает, что события могут появлятся с некоторой частотой внутри дня и иметь различное значение для величины будущего движения цены.
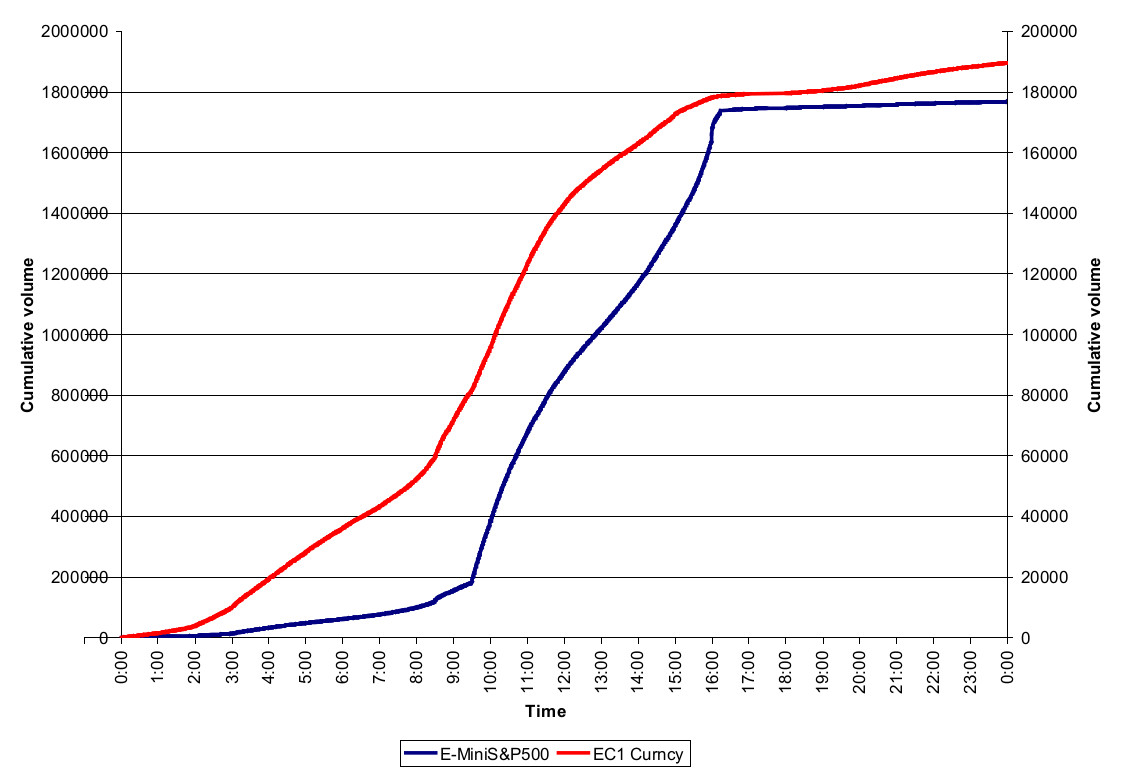
Очень важным аспектом моделирования на высоких частотах является то, что сделки разделены не равными интервалами времени. Трейды приходят с нерегулярной частотой и одни важнее других, так как содержат разные информационные величины. Например, на рисунке в заглавии поста показаны графики фьючерсов Е-mini S&P500 и EUR/USD, демонстрирующие разную внутридневную сезонность. Приход новой информации на рынок вызывает волны решений, переходящие во всплески объемов. Информация, связанная с разными продуктами поступает в разное время, что генерирует различную внутридневную сезонность по объемам.
В данной работе, вместо использования календарного времени, мы применяем время по объемам. Идея состоит в том , что интервал времени между сделками коррелирует с присутствием новой информации, диктуя наш выбор вместо календарного времени. Это выглядит разумно, ведь чем больше информации, тем больше она привлекает объема в сделках. Если одна пришедшая новость генерирует в два раза больше объема сделок, чем другая, мы получим в два раза больше наблюдений, таким образом удвоив их вес в выборке.
Пакетирование по объему
Из примера выше, если мы возьмем один интервал выборки фьючерса E-mini S&P500 каждые 200 000 контрактов в прошедших сделках, то получим в среднем 9 интервалов в день. В очень активные дни мы увидим в разы больше интервалов, чем 9, а в неактивные дни - меньше. Так как фючерс на EUR/USD имеет дневной объем примерно в 10 раз меньше объема E-mini, то для получения 9 интервалов, нам нужно принять расстояние по объему между соседними интервалами в 20 000 контрактов.
Для получения выборки по объемам, мы сгруппируем последовательные сделки в пакеты с равным объемом, который определяется нами произвольно, и обозначим его буквой V. Пакет объема - это число сделок с общим объемом V. Если в последней сделке для комплектации пакета объема больше, чем нужно, лишний объем уходит в следующий пакет. Обозначим 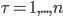 - индекс пакета. Разбиение на пакеты позволит нам разделить торговую сессию на периоды сравнимого информационного содержания, в которых разница объемов несет значимое экономическое влияние на провайдеров ликвидности.
- индекс пакета. Разбиение на пакеты позволит нам разделить торговую сессию на периоды сравнимого информационного содержания, в которых разница объемов несет значимое экономическое влияние на провайдеров ликвидности.
Синхронизированная по объему вероятность информированной торговли (VPIN)
Стандартная модель PIN использует только число покупок и продаж для извлечения знания об информационной структуре торгов, и не применяет значение объема. На высокочастотных рынках получение числа сделок проблематично. Возвращаясь к теоретическому нахождению PIN, нам требуется информация о намерениях информированных и неинформированных трейдеров. Связь между торговыми намерениями и транзакциями на рынке очень зашумлена, так как намерения могут быть разделены на много частей для уменьшения воздействия на цену, один ордер может произвести много сделок, и несущие информацию сделки могут происходить через разные типы ордеров. По этим причинам, мы обрабатываем каждую сделку, как если бы она была суммой сделок с минимальным объемом ( например, сделка на 5 контрактов по некоторой цене p представляется как 5 сделок по 1 контракту, каждый по цене p). Это допущение учитывает интенсивность в нашем анализе.
Для каждого интервала ожидаемый торговый дисбаланс ![E[|V_{\tau}^S-V_{\tau}^B|]\approx\alpha\mu](http://www.quantalgos.ru/wp-content/plugins/latex/cache/tex_d93e5d7019caa141a460e787492efc1e.gif) и ожидаемое общее число сделок
и ожидаемое общее число сделок ![E[V_{\tau}^S+V_{\tau}^B]=\alpha\mu+2\epsilon](http://www.quantalgos.ru/wp-content/plugins/latex/cache/tex_b8874b3143b30c0cd45e3b83452ea11a.gif) (символы S и B означают продажу и покупку соответственно). Пакетирование по объему позволяет нам получить эти значения очень просто. В частности, вспомним, что мы разделили торговый день на равные по объему временные интервалы и вывели каждый пакет объема как эквивалент пришедшей информации. Это означает, что
(символы S и B означают продажу и покупку соответственно). Пакетирование по объему позволяет нам получить эти значения очень просто. В частности, вспомним, что мы разделили торговый день на равные по объему временные интервалы и вывели каждый пакет объема как эквивалент пришедшей информации. Это означает, что 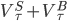 постоянно и равно V, для всех
постоянно и равно V, для всех 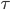 . Тогда мы аппроксимируем торговый дисбаланс средним торговым дисбалансом из n пакетов.
. Тогда мы аппроксимируем торговый дисбаланс средним торговым дисбалансом из n пакетов.
Из величин вычисленных выше, мы можем получить синхронизированную по объему вероятность информированной торговли - VPIN метрика токсичности потока заявок:
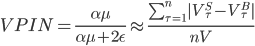
Нахождение VPIN требует выбора V, объема в каждом пакете, и n, числа пакетов, используемого для аппроксимации ожидаемого торгового дисбаланса. Для нашего примера, выберем V как одну пятидесятую от среднего дневного объема. Если затем мы установим n=50, то мы будем вычислять VPIN по 50 пакетам, которая в день среднего объема будет соответствовать нахождению дневного VPIN. Наши резельтаты робастны для широкого выбора значений V и n, что мы покажем позднее.
VPIN обновляется после прихода каждого пакета объема. Таким образом, когда 51 пакет заполнен, мы отбрасываем 1 пакет и вычисляем новый PIN по пакетам 2-51. Мы обновляем метрику в привязке к объемам по двум причинам. Во-первых мы хотим, чтобы скорость обновления соотвествовала скорости, с которой информация прибывает на рынок. Мы используем объем в качестве посредника для меры поступления информации, чтобы добиться этой цели. Во-вторых, мы хотим, чтобы каждое обновление было основано на сравнимых количествах информации. Объем может быть очень разным в течение сегментов торговой сессии, и сегменты с низким объемом могут не содержать новой информации. Таким образом, обновление VPIN в привязке к равным интервалам времени может привести к обновлениям с гетерогенным количеством информации.
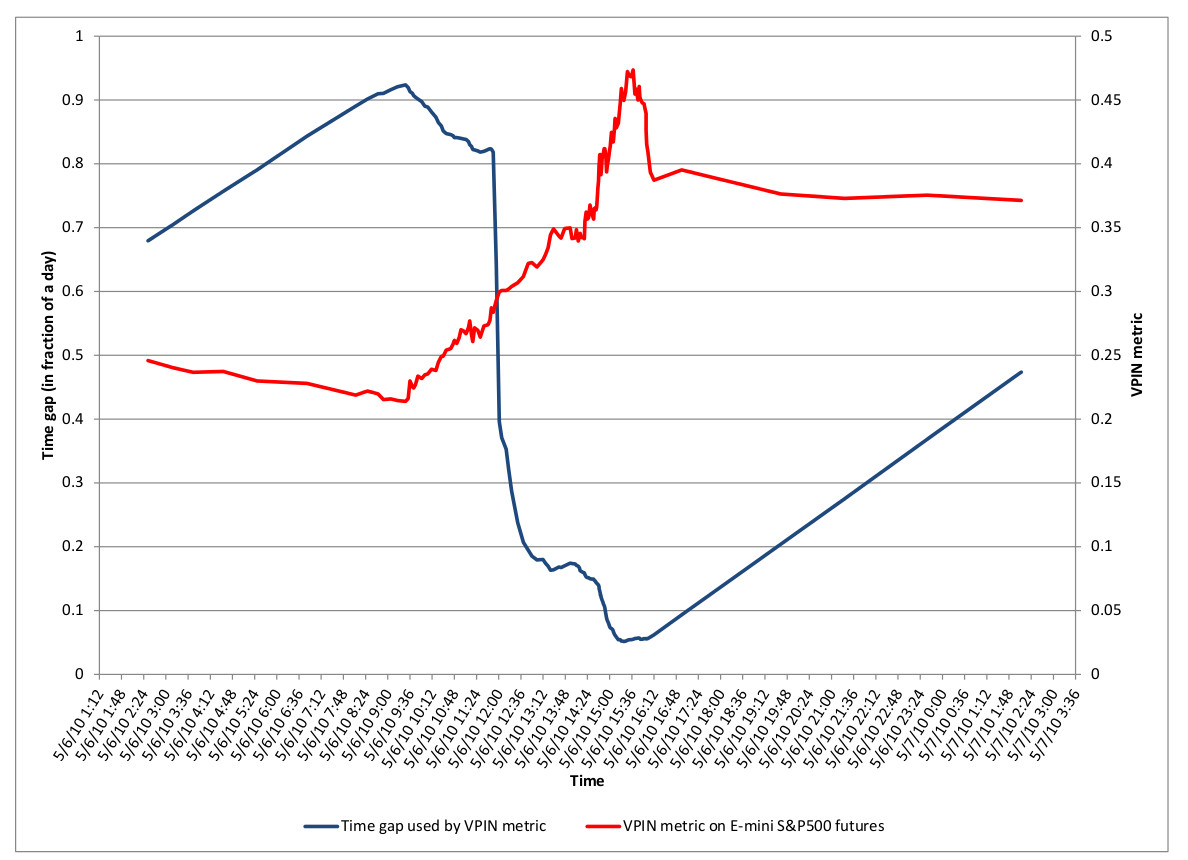
Для примера, возьмем торги фьючерсом E-mini S&P500 на 6 мая 2010 года. Объем в этот день (напомним, имел место большой обвал котировок) был экстремально высоким, так что наш алгоритм произвел 137 вычислений VPIN , сравните с 50 оценками в день со средним объемом. Так как наш размер выборки равен 50, временной интервал для одного значения VPIN на 6 мая 2010 года был всего несколько часов, сравнивая с 24 часами в средний день. На графике ниже показано, как временные интервалы становятся эластичными, соответствуя интенсивности торгов ( посредника для меры прибытия информации). В 9:30 данные, используемые для вычисления VPIN занимают почти целый день. После открытия биржи 6.05.2010 наш алгоритм обновляет VPIN более часто, основываясь на более коротких временных интервлах. В 12:17 период вычисления составляет только полдня. Отметим, что уменьшение временного периода не приводит к зашумлению оценок, изменения VPIN следуют продолжительному тренду. Причина состоит в том, что объемное пакетирование производит сравнимые количества информации для каждого обновления.
Модели GARCH являются альтернативным способом работы в условиях кластерности волатильности высокочастотных данных, разделенных на временные интервалы. Применение объемного пакетирования уменьшает такую кластерность, так как получаемая оценка основана на интервалах с равным объемом.В связи с тем, что большие движения цены ассоциируются с большими объемами торгов, разбиение по объемам может рассматриваться, как разбиение по волатильности. В результате статистическое распределение набора наблюдений ближе к нормальному и менее гетероскедастично, чем при разделении на равные временные интервалы. Таким образом, применение объемного пакетирования является простой альтернативой использованию моделей GARCH.
В следующей части рассмотрим применение VPIN на реальных биржевых данных.


Сообщение